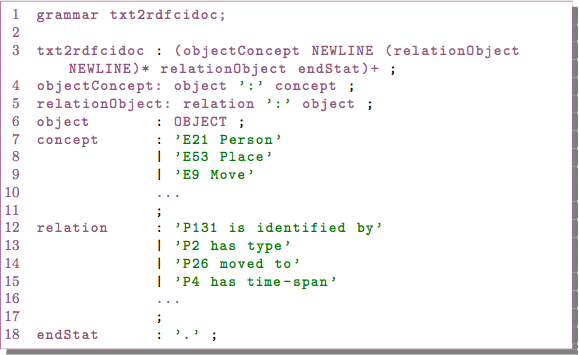
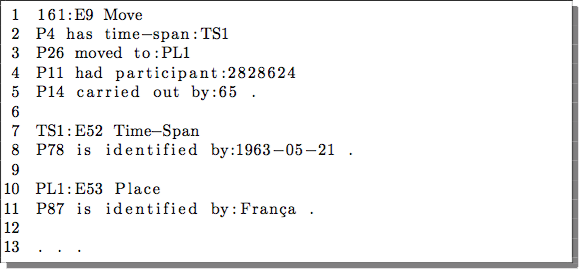
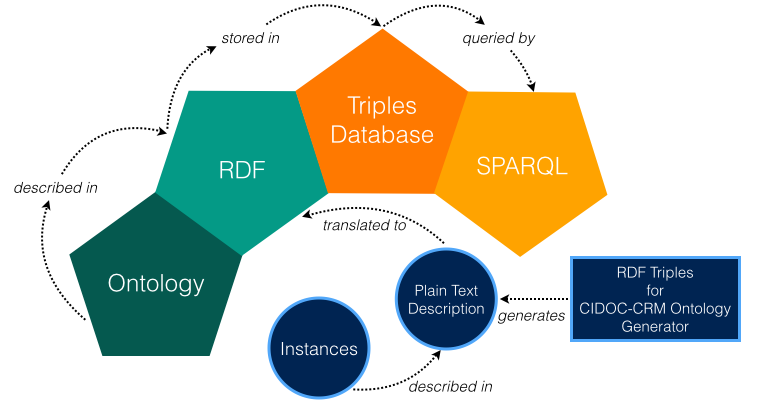
CIDOC-CRM Core Structure
Hint: hover the mouse over the concepts to see the meaning of each one.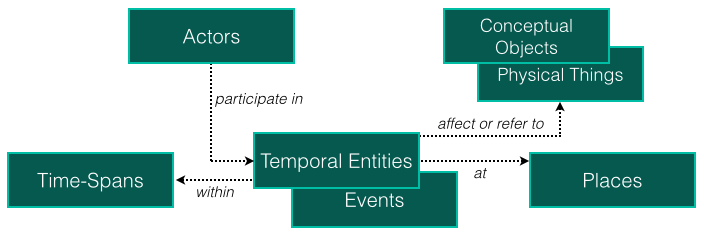
The CIDOC Conceptual Reference Model (CRM) provides definitions and a formal structure for describing the implicit and explicit concepts and relationships used in cultural heritage documentation.
The CIDOC CRM is intended to promote a shared understanding of cultural heritage information by providing a common and extensible semantic framework that any cultural heritage information can be mapped to. It is intended to be a common language for domain experts and implementers to formulate requirements for information systems and to serve as a guide for good practice of conceptual modelling. In this way, it can provide the "semantic glue" needed to mediate between different sources of cultural heritage information, such as that published by museums, libraries and archives.
See more at: CIDOC-CRM webpage
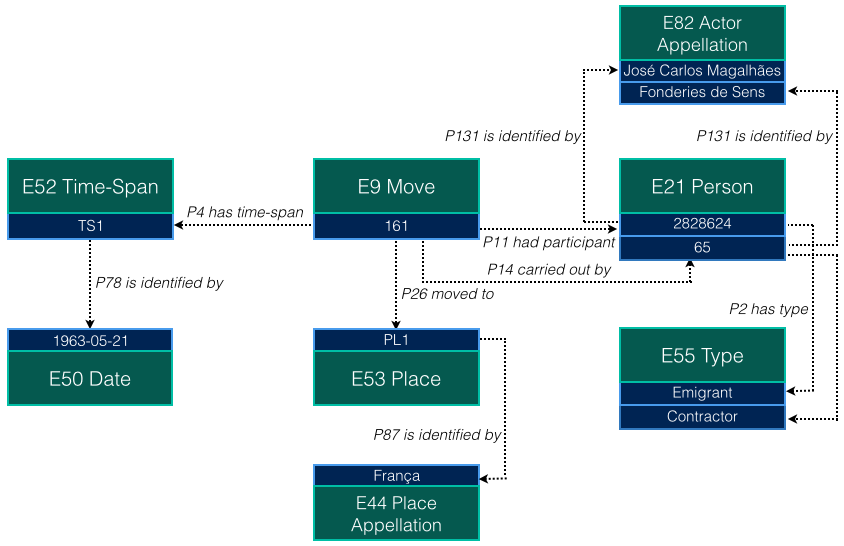
CIDOC-CRM is an event-based ontology where the main entities are related to Temporal Entities. As their name implies, Temporal Entities are concepts related to events in the past and because of this, they are related to a temporal length of events (period), so they can have date and time associated to the Time-Spans entity. The Actors, Conceptual Objects, Physical Thing and Places classes can not be directly linked to time (Time-Spans), so they need to be associated to events (Temporal Entities).
A Place can be anything that describes a location (geographical or e.g., in the bank of the Douro River or on top of Eiffel Tower).
Actors are entities that hold a legal liability. An actor can be an individual or a group; the first one is related to a person and the second one can be associated to a company, for example. Actors interact with things (Conceptual Objects and Physical Things) through events.
A Physical Thing is something that can be physically destroyed and, case some part is preserved, it can be turned into something new. By other hand, Conceptual Objects can not be crashed. For instance, a physical thing like a smartphone, or a magazine can be destroyed, but the information (content) related to that physical thing can not. To destroy a Conceptual Object it is necessary to extinguish the source, i.e., anything that represents that concept, including people.
Things in CIDOC-CRM can have Appellations. They can be a name, an identification number, etc. Furthermore, different organizations have distinct classification types. In CIDOC-CRM, these classifications are called Types and they classify things. For instance, events can have diverse types like birth, marriage, race, earthquake, flood, war, etc. Both Appellations and Types can be related to any entity.