Oveia
- A topic map builder
The ontology extractor -- Oveia (more details in
\cite{Oveia04}) -- is based on ISO/IEC 13250
Topic Maps. Oveia extracts information fragments from
heterogeneous information systems according to
an XSDS specification and builds the topic map
according to an ontology specified in XS4TM
language.
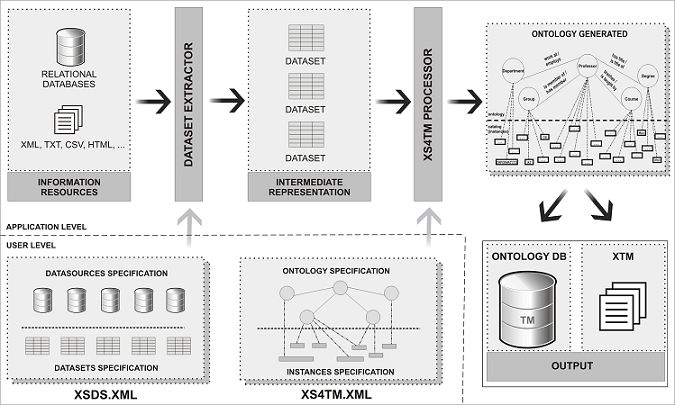
The Oveia architecture is shown in figure below
and it is composed mainly of five components.
The dataset extractor receives an XSDS specification --
providing metadata about the \textit{physical data sources}
that will be used to query each source in order
to get the data needed for the ontology construction -- and generates
the intermediate representation (called
datasets) -- containing the data (in a unified representation)
extracted from resources. The XS4TM processor takes as
input these datasets and an XS4TM
specification generating a topic map, in an internal format.
An output generator stores the topic map
in an OntologyDB or in an XTM file.
The following subsections describe this architecture in detail.
XSDS -- XML Specification for DataSources
Oveia supports the concept of extraction drivers. A
driver extracts data from a data source and
store it in an intermediary representation, called datasets.
XSDS language defines the transformations and
filters over the data sources. XSDS gives precise information
about each data source that should be scanned to extract topics
and associations.
An XSDS specification has two parts: datasources and
datasets. The first one defines the path to
the physical resources. Each resource is defined in a
<datasource> element. This element has a set of
attributes that indicate which extractor driver
will be used and the necessary parameters, because each driver has its
own attributes. The second part of this
specification is defined in a <datasets> element.
It declares which data (record fields or DTD elements) must be
extracted from each datasource. Each
datasource can be used to declare several datasets.
Datasets: Intermediate Representation
The datasets compose the intermediate representation that
contains the extracted data from the resources.
Each dataset has a relation to an entity in these resources and
it is represented through a table, where each
line is a record following the structure specified in
XSDS. The datasets representation guarantees that
Oveia sees an uniform data structure
that represents all the participating resources.
The dataset declaration is composed by a query to extract the
data from resources. Each dataset has an
unique identifier. This identifier will be used throughout the
architecture to reference a particular dataset.
The fundamental idea is that all objects have labels that describe
their meaning. For instance, the following
object represents a member's category: <1, PhD>, where the
string 1 is a identifier of this
category, and PhD is a human-readable label. The datasets are
very simple, while providing the expressive
power and flexibility needed for integrating information
from disparate sources.
Dataset Extractor
The Dataset Extractor is a processor that reads the input files
and parses them to get desired data into the
datasets, in agreement with an XSDS specification.
The Dataset Extractor is composed of several extraction drivers
(at moment, two), each one responsible for
handling specific type of source. The driver uses the appropriated
mechanisms to make the connection (e.g. JDBC --
Java DataBase Connectivity -- for databases, and an
XML parser for annotated documents), and then the extraction
data is performed in the query language
adequate to the type of source in use: SQL will be used to extract
information from a relational database while
XPath will be used for the extraction in XML documents. Finally, the
data extracted is stored in the datasets.
At this moment, two extractor drivers were developed: to connect with
databases; and to deal with XML documents. The
implementation of new extraction drivers for other kind of resources
will happen in a demand driven way.
XS4TM -- XML Specification for Topic Maps
XS4TM is a domain specific language conceived to specify the process
of ontology extraction from information systems;
in our case, from the dataset.
Looking at a topic map an ontology designer can think of it as having
two distinct parts: an ontology and an object
catalog (instances). The ontology is defined by topic types,
association types, occurrence role types, etc.
The catalog is composed by a set of pointers to information
objects that are present in the resources and are linked to the
ontology. So, a specification in XS4TM is
composed of two parts:
Ontology: the definition of the ontology requires in XS4TM the
same effort as in XTM; it is necessary to
specify every topic type, association type, occurrence type, ...;
Instances: the instances definition describes each topic and
association that will be extracted from the
information resource.
The XS4TM Context Free Grammar is based in
XTM 1.0
DTD. The ontology and instances
elements have the same syntax that the topicMap element in XTM model.
The XS4TM language is intended to make the specification of Topic Maps
extraction more flexible. However, the use of XS4TM is not much more difficult because this
language is an extension of the XTM standard; it means the XS4TM DTD includes and augments the XTM DTD.
In XS4TM, the ontology is specified like in XTM: with the same elements and attributes. So, if
the designer knows XTM syntax, he does not need to learn another syntax to specify ontology
in XS4TM.
XS4TM processor
This component uses the XS4TM specification and retrieves the
information it needs to build the ontology from the
datasets. It is an interpreter that takes
advantage of the information organization in datasets (an internal universal
representation for extracted data) and generates all the associations between the relevant topics according
to XS4TM.
The XS4TM processor's behavior can be described in three steps: reads
the the XS4TM specification and extracts from the
datasets the topics and associations
found; creates the topic map; finally, stores it into an
OntologyDB or an XTM file.
Oveia Output -- OntologyDB or XTM file
Once we chose XML as our development framework, the first version of
the output generator stored the topic map to a file in XTM format. However, XTM files can grow
exponentially. Huge XTM files are space and time consuming making their processing a hard task,
specially from the web server side; and the performance tends to be worse as the interaction
activity grows. So, in real cases it is crucial to find other ways to store very big ontologies.
Therefore, it was decided to use also database technology besides XTM files.
The Topic Maps model maps quite well into the relational model. This
way it was decided to create a relational model for Topic Maps, named
OntologyDB, following the structure mapping
adopted in \cite{XMLDatabase2000}. This model is easy to understand
and to implement systematically.
The current version of the output generator can export the topic map
to an XTM file and to a relational database. In the second case, the topic map, automatically
generated by Oveia, is converted into related tables and stored in the
OntologyDB.
In practice, there is a processor that stores an XTM document into an
OntologyDB. This processor also allows the conversion in the opposite direction:
extract XTM documents from an OntologyDB.
|