GQE
GQETo achieve the desire result - assessing the quality of grammars and there foward languages - the system must first read and validate the input grammar, written in ANTLR, perform all the metrics calculation and then reasoning about each metric value to produce the Quality Report or Quality Assumptions automatically. These assumption are all reasoned by this tool regarding the Grammar Quality Factor and how one is affected by each metric:
- Usability while language generator of the grammar as a tool for sentences derivation of a language:
- ease of understanding
- ease of learning
- ease of maintenance
- Efficiency while program generator of the grammar as tool for languages processors derivation:
- efficient recognition of sentences from the generated language
- efficient processor automatic generation
Architecture
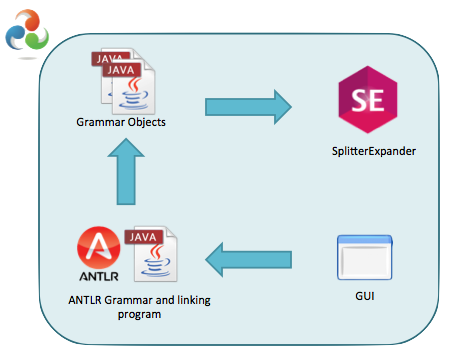
GQE tool is composed by four main components, as shown in the following figure: the SplitterExpander component, the Grammar objects(Java classes), the ANTLR linking component and the graphical user interface(GUI). All this components work together to perform the desire results, as previously mentioned. The SplitterExpander component is used for the assessment of the lexicographic metrics. The ANTLR linking component is the one responsible to execute the parser and the lexer generated in the initial phase, from the Attribute Grammar designed to describe ANTLR's meta-language. All the metrics calculation process is embedded in the attribute grammar, it is there that the Java classes, which represent the object grammar, are fed to store the value from that process as well as the call to SplitterExpander component. Finally, the GUI uses the Java classes to fetch the metrics values and display them.
Grammar Objects
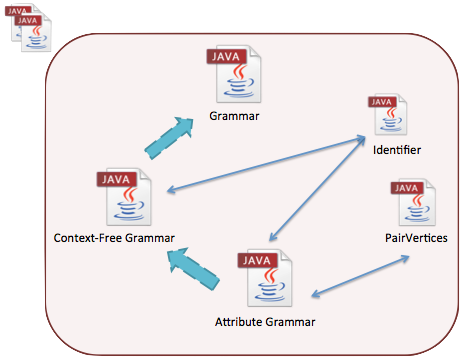
Grammar objects are the Java classes that were created to conceptualize the notions of Context-Free Grammars and Attribute Grammars. Basically, the idea was to create an Java abstract class to describe the object Grammar, then from that, create an extension of that class, with its own characteristics, to specify the object Context-Free Grammar and from this extension to create yet another extension to specify the object Attribute Grammar, just like stated in their definitions.
The main function of this component is from one hand to store the values outputted from an grammar recognition and from another hand to supply the user interface with the metrics already calculated. The benefits of this solution is to take all the calculation process of the grammar, thereby making the grammar more clean and readable. Another important aspect is the easiness to maintain the application as well as its own development process. In the future any update on the application can be done just by linking a value from the grammar recognition and changing a metric definition in the desire grammar object, for example.
Identifier class is responsible to treat and read the results provided by the SplitterExpander regarding the lexicographic metrics. As for the PairVertices is used for the building the Local Dependencies Graph and the Dependencies Grpah between Symbols.
ANTLR linking Component
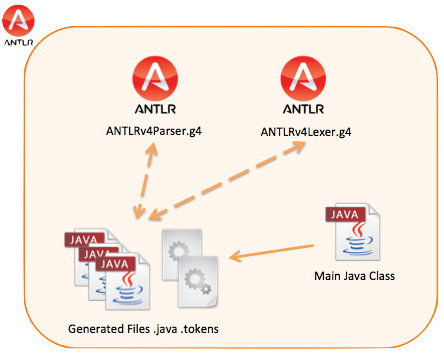
This component is an important part of all GQE structure, not because of the complexity presented in it, but because of its function and what it represents. The main function of this component, as detectable from this section name, is linking all the ANTLR files with the other components, more precisely the Grammar Objects and the User Interface. At the beginning of the input grammar recognition process, a Java object is created(Context-Free Grammar or Attribute Grammar) and initialized. In the end the User Interface retrieves this object from this component and display the metrics.
From the ANTLRv4Parser.g4 and ANTLRv4Lexer.g4 files, the ANTLR tool will generate a .tokens and a .java file for each one. The purpose of the main class is to create a lexer and parser object(with the help of the generated files) and executing the parsing process. The start symbol of the grammar is grammarSpec and the input stream come from an input file, selected by the user.
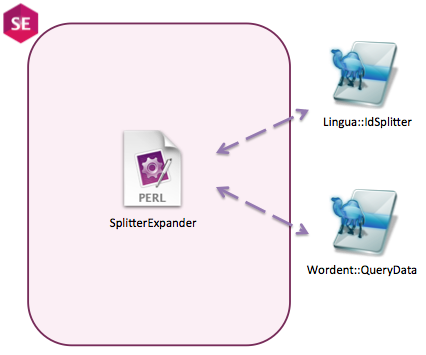
SplitterExpander
The SplitterExpander is a program developed in Perl programming language responsible to help on the assessment of the lexicographic metrics, for both Context-Free Grammars and Attribute Grammars. From the definition in which it is established the validity of an Identifier by verifying if it derives from a concept name or not, this program was created with the desire to perform three main tasks:
- to split the Identifier into logical pieces, if some splitting pattern were found or both, such as the CamelCase technique or the '\_' (underscore) separator technique;
- to expand the Identifier to the correct concept name, if the Identifier is a prefix or if it was divided in pieces to expand each one to the correct concept name;
- to validate the syntax of the Identifier;
All the tasks listed before are achieved by the SplitterExpander with the help of two other programs: a perl module called Lingua::IdSplitter and other natural processing language tool named Wordnet.