
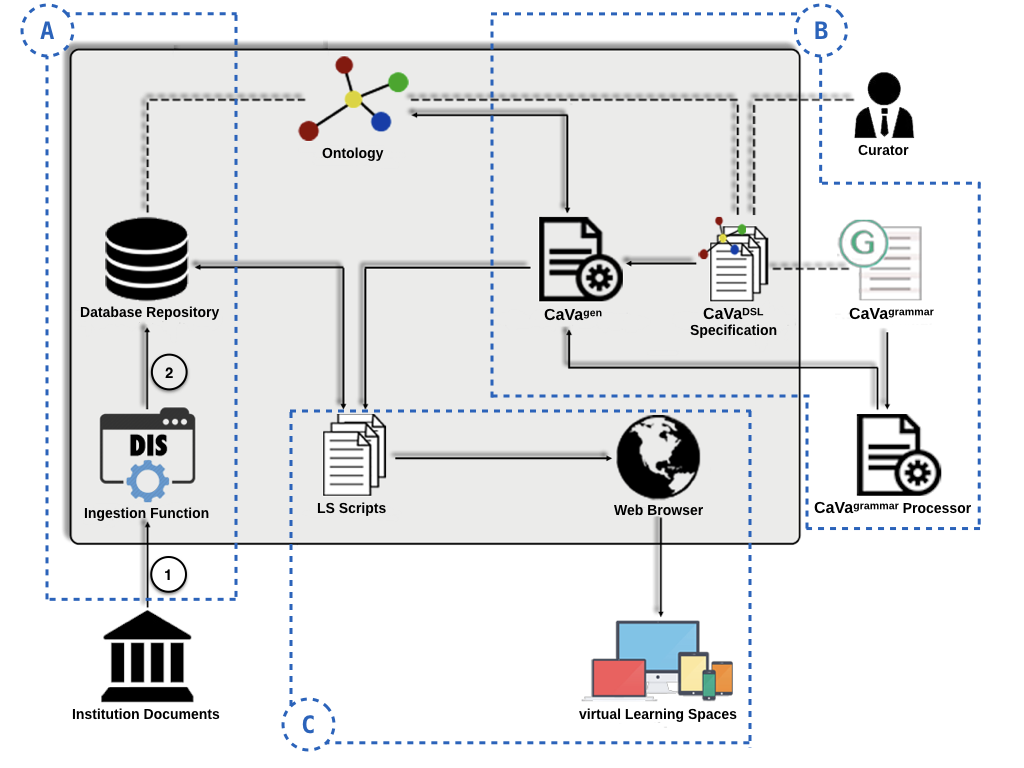
In addition to the various CaVa modules, there is a basilar component: the ontology, that serves to specify the knowledge domain that corresponds to the institutional information repositories. The actual input to CaVa (associated to module B) is the Learning Space Specification, written in CaVaDSL, that determines which concepts should be exhibited and how they should be placed in the final virtual Learning Spaces by the Curator.
Module A, that is a kind of back office of this framework, is composed of the Database Repository and the Ingestion Function with the aid of a Document (Data) Ingestion System (DIS) to upload the institution documents information and data management. Module B is made up of four components that are CaVagen (a specification engine), CaVaDSL Specification, CaVagrammar and CaVagrammar Processor, which processes the grammar and generates the specification engine. Module C is composed of the generated LS Scripts, the Web Browser, and the virtual Learning Space, which is the target or output of the CaVa System.
This architecture was not designed for a specific domain. Instead, it shall support any knowledge domain associated with museums, libraries, archival or schools.
The objective of CaVasettler is to collect physical documents information from the institution Documents (the actual input of a DIS) and populate the digital database repository aiming at displaying the document's knowledge in virtual Learning Spaces. These are the components for this module:
To generate the virtual Learning Spaces, which have the objective of imparting knowledge about a specific domain to the end-users, it is necessary to describe the knowledge implicit in the information contained in the sources (database repositories).
Depending on the Database Repository type, some extra tasks are needed (e.g. if the repository is a relational database, it is necessary to do the mapping between the ontology and the database, aiming at achieving the database instances).
It contains the main components necessary to achieve the objective of CaVa. CaVaprocessor is the machinery that interprets the CaVaDSL language specification (the CaVa input, manually written by the Curator) and uses CaVagen to produce as output, the virtual LS scripts necessary to render the desired final virtual Learning Space. Remembering that the input of this module is a specification written in the specific language CaVaDSL. To be clear, these specifications are built manually by the Curator that should have knowledge about (1) the language rules defined by CaVagrammar, and (2) the main ontology that describes the documents repository. The components of the CaVaprocessor module are detailed below:
It is the module responsible for recognizing the LS Scripts generated by CaVagen and rendering, via a web browser, the virtual Learning Space described in a CaVaDSL Specification. The components of the CaVarender module are detailed below: